Hash-Table
使用基于红黑二叉查找树实现的查找算法,在平均情况下可以达到logN的效率。算法时间复杂度中,最小最优的就是常数级别的复杂度。有没有一种算法可以突破logN的查询复杂度到达常数级别的效率?答案就是散列表(Hash-Tables)
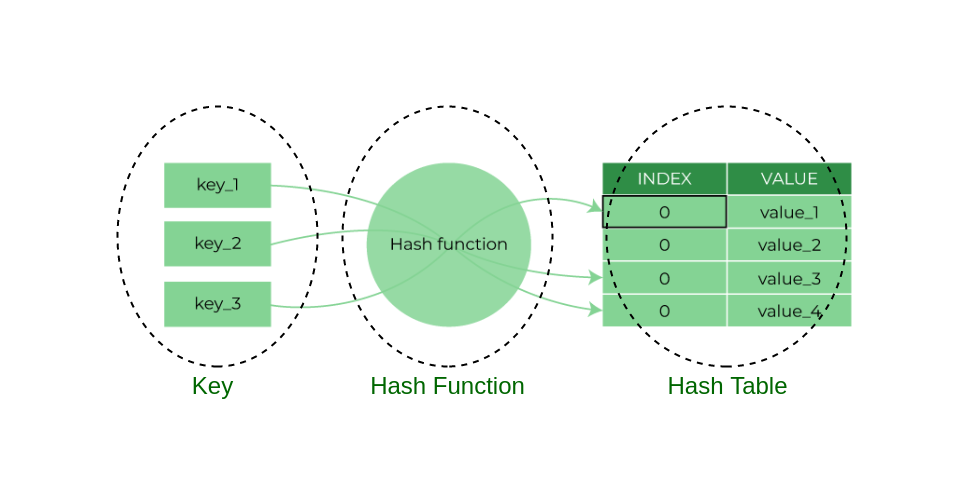
使用散列表需要将键转化为数组的索引,进而使用这个索引实现对数组中键值对的快速访问。这就产生了两个需要解决的问题:
怎么由键转化为数组索引;
如何处理转化后索引的冲突。
将键转化为数组的索引需要一个 散列函数 , 这个函数最理想目的是将可能用例的不同的键都可以转化为不同的索引值。但是这样的散列函数目前是不存在的,因为我们需要将 key 映射到一个有限的索引范围内,所以转化时一定会出现索引冲突的情况,也就是多个键转化后对应一个索引值。在散列查找中解决索引冲突一般使用两种方法: 拉链法 和 线性探测法 。
1. 散列函数
散列函数用于解决上述第一个问题,将键转化为数组索引。如果我们有一个长度为M的数组用于存储键值对,那么我们就需要一个可以将任意键值转化为该数组的索引范围( [0, M-1] )内整数的 散列函数 。散列函数应该是能使所有键分布均匀且易于计算。
散列函数的设计与键的类型有很大的关系。确切的说,对于每一种类型的键我们都需要寻找一个与之对应的散列函数。
1.1 正整数
将整数散列最常用的方法是:除留余数法 。选择一个大小的为素数 M 的数组,对于任意的整数键 k,计算 k 除 M 的余数作为在数组中的索引。此散列函数能很有效的将键散布在 [0,M-1] 的范围内。选取素数是因为其特殊的数学性质能更好的将键散列,选取其他数(最坏的情况是:如果键是10进制数而数组的大小为10^k,那么散列函数就只能利用到键的后K位数)可能会产生很多的索引冲突。
1.2 浮点数
如果键是一个 0 到 1 之间的浮点数,我们可以将其乘以 M 后四舍五入得到一个整数作为其的索引值。此方法便于理解和计算,但是浮点数小数的低位对散列结果的影响没有高位的大。在一些特殊情况:浮点数小数的高位都一样而低位不同,散列的情况就可能非常的糟糕。解决这个问题的方法是将键转化为二进制表示,然后再使用除留取余法。
1.3 字符串
对于字符串这种一般较长的键,也可以使用除留取余法。只需要将字符串当作一个较大的整数就行。具体例子如下:
| |
如果 R 比任何字符的值都大,这种计算相当于将字符串当作一个 N 位的 R 进制值,将它除以 M 并取余。
1.4 组合键
如果键的类型含有多个整型变量,我们可以和 String 类型一样将它们混合起来。例如,假设被查找的键的类型是 Date,其中含有几个整型的域: day(两个数字表示的日), month(两个数字表示的月)和 year(4 个数字表示的年)。我们可以这样计算它的散列值:
| |
只要 R 足够小不造成溢出,也可以得到一个 0 至 M-1 之间的散列值。
1.5 将hashCode()返回值转化为一个数组索引
由于每种数据类型都需要相应的散列函数,于是 Java 令所有数据类型都继承了一个能够返回一个32 比特整数的 hashCode() 方法。每一种数据类型的 hashCode() 方法都必须和 equals() 方法一致。因为我们需要的是数组的索引而不是一个 32 位的整数,我们在实现中会将默认的 hashCode()方法和除留余数法结合起来产生一个 0 到 M-1 的整数,方法如下:
| |
总的来说,一个优秀的散列函数应当满足以下三个要求:
- 一致性:等价的键必然产生相同的散列值。
- 高效性:计算简便,容易。
- 均匀性:均匀的散列所有的键。
2. 基于拉链法的散列表
在能将键转化为数组中的索引以后,我们就需要解决问索引冲突的问题,也叫碰撞处理。拉链法是上述解决散列索引冲突方法的其中一种,其原理是:将数组中的每一个元素指向一个链表,索引冲突的键都存储在一张链表中,链表中的每一个结点都存储了键以及其对应的值。
此方法的局限性也在链表上,链表过长会严重影响查询和插入的性能。所以在确定数组的大小时,通常需要申请一个长度足够大的数组,使的所有的链表都尽可能的短从而保证查找的高效性。
Java
| |
实现中使用静态内部类Node作为每一个结点元素的类型,每一次put()插入操作如果发送了索引冲突都会将新的元素插入到索引位置链表的表头,变成首元素。
查找元素分为两步:
根据键的散列值查找到对应的链表;
沿着链表顺序查找到键对应的元素。
当你能够预知所需要的符号表的大小时,这段短小精悍的方案能够得到不错的性能。目标是选择适当的数组大小 M,既不会因为空链表而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
3. 基于线性探测法的散列表
除了拉链法,另一种类型的方法是用大小为 M 的数组保存 N 个键值对,其中 M>N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为开放地址散列表。
开放地址类的散列表的核心思想是与其将内存用作链表,不如将它们作为在散列表的空元素。开放地址散列表中最简单的方法叫做线性探测法:当发送索引冲突使,我们直接检查散列表中的下一个位置(将索引值加 1)。
线性探测法插入键值对的流程:用散列函数找到键在数组中的索引,检查其中的键和被查找的键是否相同。如果不同则继续查找(将索引增大,到达数组结尾时折回数组的开头),直到找到该键替换value或者遇到一个空位置插入元素。基于线性探测法的散列表完整实现如下:
Java
| |
根据科研人员的大量科学研究:在散列函数能较为均匀的将键散布在区间[0, M-1]内的假设下。当散列表快满的时候查找所需的探测次数是巨大的:在全满时会一直探测进入无限循环。但是当使用率小于 1/2 时,探测的预计次数只在 1.5到 2.5 之间。
所以使用线性探测法实现散列表时,我们很有必要动态的调整数组的大小,使探测次数达到一个合理的值。上述实现中在每一次插入元素前判断散列表的利用率是否以及达到 1/2 达到了将数组扩容为原来的2倍。使散列表的利用率一直小于 1/2 从而确保探测次数的合理。
动态调整数组的大小解决了很多问题,但是 resize() 方法每执行一次是会消耗大量资源的,特是在数组长度较长以后。因为每一执行次 resize() 都会在新数组长度下将所有以前的键值对重新插入。由于可以认为 hash() 是常数级别的操作,所以 resize() 的时间复杂度大约为线性级别。 幸运的是数组越大,需要调整的情况更少。
4. 散列表的优缺点分析
各种符号表实现性能的比较如下表:
| 算法(数据结构) | 查找(最坏) | 插入(最坏) | 查找命中(平均) | 插入(平均) | 内存使用(字节) |
|---|---|---|---|---|---|
| 顺序查询(无序链表) | N | N | N/2 | N | 48N |
| 二分查找(有序数组) | lgN | N | lgN | N/2 | 16N |
| 二叉树查找(二叉查找树) | N | N | 1.39lgN | 1.39lgN | 64N |
| 2-3 树查找(红黑树) | 2lgN | 2lgN | 1.00lgN | 1.00lgN | 64N |
| 拉链法 (链表数组) | <lgN | <lgN | N/(2M) | N/M | 48N+32M |
| 线性探测法(并行数组) | clgN | clgN | <1.5 | <2.5 | [32N, 128N] |
基于上表以及上文分析得到以下结论。
优点:
- 理论上散列表能够支持和数组大小无关的常数级别的查找和插入操作(在所有符号表实现中最优)。
缺点:
每一种数据类型的键都需要一个优秀的散列函数,散列函数的好坏很大程度决定算法性能。
散列函数的计算可能复杂而且昂贵。
难以支持有序性相关的符号表操作。
图片资料来自:
Algorithms (4th Edition)
| Jun 14 | Binary-Search-Tree | 3 min read |
| Jun 14 | Red-Black-BST | 4 min read |
| Jun 12 | Binary-Search | 2 min read |
| Jul 24 | Shortest-Path | 9 min read |
| Jul 21 | Minimum-Spanning-Tree | 7 min read |